Chris Padilla/Blog
My passion project! Posts spanning music, art, software, books, and more. Equal parts journal, sketchbook, mixtape, dev diary, and commonplace book.
- Navigating to the correct page by button click (it's a SPA, so a necessary step instead of by URL directly.)
- Grabbing the column index for row values in the table header
- Iterating through the rows and extracting the data
- The user clicks the "Sign in with Google Button"
- From there, they select their account, sign in, and provider permission to your app.
- An Authorization code is sent back to your app
- The authorization code is then used in another round to get tokens from Google Servers.
- Refresh and access tokens are returned from that server
- These are stored with your application for using the Google API.
- Centralized source of truth for session data.
- Seamless update when user role or permissions change.
- Light on application logic needing to be written on the client.
- Easy management: can clear session in the event of logging out on all devices or a suspended account.
- Limited in a distributed system. All session checks must go through the main site and db.
- Storage costs: db usage scales with active users.
- DB access costs: requires a roundtrip to DB for every request just to verify session.
- A DB breach means this information is compromised.
- Has potential to be a "stateless" login mechanism, allowing for light overhead.
- Lower DB and access cost.
- In a distributed system, so long as you verify the secret, it's possible to verify the user across a cloud infrastructure.
- Added app infrastructure needs to be written to handle token expiration, refreshing, etc.
- Should the token be compromised, extra steps need to be taken to invalidate the user.
- A popular approach is to include user permissions with the token. If that's the case, there needs to be logic written to handle the case where there is an update and the token needs re-encoding
Valentine

Had a lovely Valentine's Day with Miranda 💙
Automation & Web Scraping with Selenium
I had a very Automate The Boring Stuff itch that needed scratching this week!
I have an office in town that I go to regularly. I'm on a plan for X number of visits throughout the year. The portal tells me how many visits I have left, but there's a catch. My plan also includes a special one-on-one consult doesn't let me know when I can redeem two special one-on-one consults as part of the package, ideally scheduled evenly through the year.
I could just put in the calendar to do this on reasonable months – April and September. But what if I kick up my visit frequency? What if I'm the business owner and I want to track this for multiple clients? What if I just want to play around with Selenium for an evening?
So here's how I automated cacluating this through the business's portal!
Selenium
If you've scraped the web or done automated tests, then you're likely familiar with Selenium. It's a package that handles puppeteering the browser of your choice through web pages as though a user were interacting with them. Great for testing and crawling!
If I were just crawling public pages, I could reach for Beautiful Soup and call it a day. However, the info I need is behind a login page. Selenium will allow me to sign in, navigate to the correct pages, and then grab the data.
Setup
Setting up the script, I'll do all of my importing and class initialization:
import os
import re
from dotenv import load_dotenv
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.common import exceptions
from selenium.webdriver.support import expected_conditions
from datetime import datetime
class Collector:
def __init__(self):
load_dotenv()
options = webdriver.ChromeOptions()
options.add_experimental_option("detach", True)
self.driver = webdriver.Chrome(options=options)
self.login_url = "https://biz.office.com/login"
self.account_url = "https://biz.office.com/account"
def run(self):
self.handle_login()
visit_history = self.get_visit_history()
self.get_remaining_visits_until_package_renewal(visit_history)
if __name__ == '__main__':
c = Collector().run()I'm storing my login credentials in an .env file, as one should! The "detatch" option passed in simply keeps the window open after the script runs so I can investigate the page afterwards if needed. The URLs are fictitious here.
So, all set up! Here's looking at each function one at a time:
Login
def handle_login(self):
AUTH_FIELD_SELECTOR = "input#auth_key"
LOGIN_BUTTON_SELECTOR = "button#log_in"
PASSWORD_FIELD_SELECTOR = "input#password"
self.driver.get(self.login_url)
self.wait_for_element(AUTH_FIELD_SELECTOR, 10)
text_box = self.driver.find_element(By.CSS_SELECTOR, AUTH_FIELD_SELECTOR)
login_button_elm = self.driver.find_element(By.CSS_SELECTOR, LOGIN_BUTTON_SELECTOR)
text_box.send_keys(os.getenv('EMAIL'))
login_button_elm.click()
# Password Page
self.checkout_page(PASSWORD_FIELD_SELECTOR, 10)
self.driver.find_element(By.CSS_SELECTOR, PASSWORD_FIELD_SELECTOR).send_keys(os.getenv("PW"))
self.driver.find_element(By.CSS_SELECTOR, LOGIN_BUTTON_SELECTOR).click()Writing with Selenium is nice because of how sequential and fluid writing the code is. The code above lays out quite literally what's happening on the page. Once I've received the page and verified it's opened, we're just grabbing the elements we need with CSS selectors and using interactive methods like send_keys() to type and click() to interact with buttons.
Something worth pointing out is wait_for_element. It's mostly a wrapper for this Selenium code:
WebDriverWait(self.driver, 30).until(
expected_conditions.presence_of_element_located((By.CSS_SELECTOR, element_selector))
)This is a point to ask Selenium to pause until a certain element appears on the screen. Cumbersome to write every time, so nice to have it encapsulated!
Get Visit History
Once logged in, it's time to navigate to the page with my visit history. The page contains a table with columns for visit date, session name, and the member name (me!) So what I'm doing below is:
def get_visit_history(self):
visits = []
ACCOUNT_HISTORY_PAGE_BUTTON_SELECTOR = 'a[href="#history"]'
headers_index = {}
self.driver.find_element(By.CSS_SELECTOR, ACCOUNT_HISTORY_PAGE_BUTTON_SELECTOR).click()
self.checkout_page(ACCOUNT_HISTORY_PAGE_BUTTON_SELECTOR, 10)
headers = self.driver.find_elements(By.CSS_SELECTOR, '#history tbody > tr > th')
for h, header in enumerate(headers):
header_text = header.get_attribute('innerText')
if re.search(r'date', header_text, re.IGNORECASE):
headers_index['date'] = h
elif re.search(r'session', header_text, re.IGNORECASE):
headers_index['session'] = h
elif re.search(r'member', header_text, re.IGNORECASE):
headers_index['member'] = h
rows = self.driver.find_elements(By.CSS_SELECTOR, '#history tbody tr')
for row in rows:
row_dict = {}
cells = row.find_elements(By.CSS_SELECTOR, 'td')
if not len(cells):
continue
if 'date' in headers_index:
row_dict['date'] = cells[headers_index['date']].get_attribute('innerText')
if 'session' in headers_index:
row_dict['session'] = cells[headers_index['session']].get_attribute('innerText')
if 'member' in headers_index:
row_dict['member'] = cells[headers_index['member']].get_attribute('innerText')
visits.append(row_dict)
return visitsCalculate Remaining Visits
From here, it's just math and looping!
Plan length and start date are hardcoded below, but could be pulled from the portal similar to the method above.
With that, I'm counting down remaining visits if an entry in the visits table is for a date beyond the start date and if it's a "plan visit". Once we've passed the date threshold, we can break the loop.
For the math – I calculate session values by dividing the full plan length, and reducing those values from the remaining visits. If there's a positive difference, then it's logged as X number of days until the consult.
def get_remaining_visits_until_package_renewal(self, visit_history):
PLAN_LENGTH = 37
START_DATE = datetime(2024, 1, 1).date()
remaining = PLAN_LENGTH
for visit in visit_history:
stripped_date = visit['date'].split('-')[0].strip()
if not re.search('plan visit', visit['session'], re.IGNORECASE):
continue
elif datetime.strptime(stripped_date, '%B %d, %Y').date() >= START_DATE:
remaining -= 1
else:
break
interval = math.floor(PLAN_LENGTH / 3)
first_session = interval * 2
second_session = interval
visits_until_first_session = remaining - first_session
visits_until_second_session = remaining - second_session
if visits_until_first_session > 0:
print(f'{visits_until_first_session} visits until first consult')
elif visits_until_second_session > 0:
print(f'{visits_until_second_session} visits until second consult')
else:
print(f"All consults passed! {remaining} remaining visits")
return remainingDone!
So there you have it! Automation, scraping, and then using the data! A short script that covers a lot of ground.
A fun extension of this would be to throw this up on AWS Lambda, run as a cron job once a week, and then send an email notifying me when I have one or two visits left before I should schedule the consult.
Will our lone dev take the script to the cloud?! Tune in next week to find out! 📺
Childhood's End
Thinking a great deal lately about the obstacles to play in art. Namely, though, how they aren't so much obstacles as much as they are just part of the journey.
From Stephen Nachmanovitch's Free Play:
Everything we have said so far should not be construed merely as an indictment of the big bad schools, or the media, or other societal factors. We could redesign many aspects of society in a more wholesome way—and we ought to—but even then art would not be easy. The fact is that we cannot avoid childhood's end; the free play of imagination creates illusions, and illusions bump into reality and get disillusioned. Getting disillusioned, presumably, is a fine thing, the essence of learning; but it hurts. If you think that you could have avoided the disenchantment of childhood's end by having had some advantage — a more enlightened education, more money or other material benefits, a great teacher — talk to someone who has had those advantages, and you will find that they bump into just as much disillusionment because the fundamental blockages are not external but part of us, part of life. In any case, the child's delightful pictures of trees mentioned at the beginning of this chapter would probably not be art if they came from the hands of an adult. The difference between the child's drawing and the childlike drawing of a Picasso resides not only in Picasso's impeccable master of craft, but in the fact that Picasso had actually grown up, undergone hard experience, and transcended it.
Slaughter Beach, Dog – Acolyte
Whistling and plucking along. My midwest emo phase continues!
Blue Horizon

Adventuring awaits
Development Containers
I saw the future in action with development containers and Github Codespaces last night! Really great presentation from Sebastian Steins and Nicolai Fröhlich from Europe!
The talk dove into Github Codespaces as well as Development Containers.
The gist is that moving the development environment to a cloud based host eliminates the friction of downloading packages, walking through the bash script that manages those downloads, and synchronizes all versions between dev environments.
Really interesting process! Nicolai highlighted that one benefit to this would be to have access to higher processing power than what's on your machine. When I was fiddling with modern development as a music teacher, I only had a $200 Chromebook, with miserable performance specs. Would have been great to play with this back then! 🙂
I'm excited to experiment more with these setups!
February Blues
Ate too many leftover holiday cookies last month, now I have the blues!
Make it so, Number One

Ground Control to Captain Picard 🪐
Understanding Tokens in OAuth Authentication
Signing in is simple, right? Check credentials from the client and they're good to go.
Not so! Especially when using a third party sign in provider like Google, GitHub, or Facebook.
I've gone through a couple of rounds implementing OAuth sign in. The biggest hurdle when having to handle some of that flow yourself is keeping track of the steps. Here today, I'll break down the how and why:
Sign In Flow
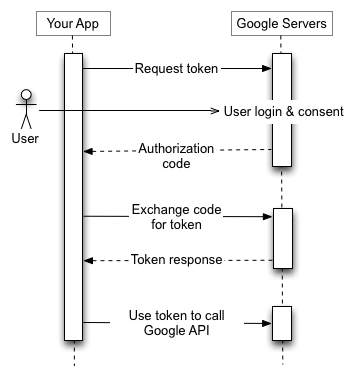
To break down the illustration above:
Largely, if you're using a library like Next Auth or Meteor.js' sign in flow, you may have some of the flow already taken care of. More than likely, though, you'll be managing the refresh and access token yourself when using Google's APIs.
API Integrations
The main benefit of signing in with an external provider is integration with your application. This could be sharing a post to Instagram, saving Spotify Playlists, or sending a generated message through gmail. From the flow above, this is where our tokens come into play.
To do that, you'll likely need to request permissions in the first step above. Google, for example, limits integration by the scopes requested from the app. You user will have to review, for example, read write access Instagram when signing in.
Once approved, the access token is short lived and will grant you access to those specific api actions. Lasting only a few minutes, they are meant for immediate use.
After expiring, the refresh token is used to request a new access token.
The reason for this dance is to mitigate the security challenges of token based authorization while also keeping the main benefit of performance at scale. I wrote a bit about this recently in my review of Database vs JWT authorization strategies.
Essentially: When an access token is given, it's difficult to invalidate it. The token is signed and verified and ready for use. Refresh tokens, however, may have some additional back end logic. A refresh token can be verified, then run through checks to see if the request has any reason to be denied ("sign me out on all devices," suspicious behavior, etc.)
While not being "stateless," this is much easier to scale than a database session. Every instance is stored in a db for that strategy, but only expired refresh tokens are marked in a system that uses a token strategy.
In Practice
At this point, you may be saying "Ok! Show me the code!"
I'll point you to the next auth docs for what this looks like in their system. The library doesn't handle token refreshing, but they've documented what it could possibly look like in your own implementation:
The key thing: check for expiration, then send a request when needed.
if (Date.now() < token.accessTokenExpires) {
return token
}
// Access token has expired, try to update it
return refreshAccessToken(token)This check can be done on each session access, though, more than likely, it would be more performant to do this just before the integration funcionality.
Lynes – Sonatina in C
Noodling!
Parker Prom

Going to the Parker Winter Formal with soon-to-be Dr. Schultz 💙
Collocation in React Server Components
At work, we're starting to spin up a Next.js app and are using the new server components! I'll share a quick look at a simple example of what it looks like and why this is a return to form for website building on the web.
A Brief History of Templating
The pendulum of web development needs and trends have swung back and forth between two sides: Heavy lifting on the client, and on the server. When thinking about an application that uses dynamic content (forums, user account sites, wikis), the major glueing that needs to happen is between data and templates. Somewhere, you have to populate a template with the requested data based on the page.
Historically, web servers handled this with templating frameworks. Popular Express templating engines include Pug and Handlebars, in C# the ASP.NET framework uses Razor pages.
A popular design pattern for these types of servers was the Model-View-Controller approach. Essentially, separating file functions based on the roles they played.
When React gained popularity, it was for it's... well, Reactivity. By handling templating on the client, smaller components were able to respond dynamically, eliminating the need for an entire page refresh.
Web performance standards, driven largely by Google's own SEO rankings of pages, have since reigned in the excessive use of client side code for public facing web pages.
And so, the pendulum is swinging back, and the React framework has taken an official stance on how to solve the issue within their own API.
By acting as a templating engine on the server, the amount of js shipped to the client majorly shrinks, allowing for faster page loads with a lighter footprint on the client. All the while, React still structures this in such a way that you can maintain some of the best features of using the JS framework, including component reactivity and page hydration.
Server Components
Examples here will come from Next.js, which at this time is required to have access to this new feature.
By default, all components are marked as server components. A server component for a page may look like this:
import React from 'react';
import db from 'lib/db';
import {getServerSession} from 'next-auth';
import authOptions from '@api/auth/[...nextauth]/authOptions';
import ClientSignIn from './ClientSignIn';
const PageBody = async () => {
const session = await getServerSession(authOptions);
return (
<div className="m-20">
Hello {session.name}!
<br />
<ClientSignIn session={session} />
</div>
);
};
export default PageBody;You can read the functional component linearly as you would a vanilla js function. We're essentially writing a script saying "get the session, await the response, then render my page."
In this simple example is one of the larger paradigm shifts as well as the power of the new feature.
Were I to write this on a client component, I would have to write a useEffect that fetched my session data, I would have to expose an API on my server, write the logic on the server to get the session data, and store the data in my client side state, and then finally render my data. Except, additionally, I would have to manage loading state on the client – showing a skeleton loader or a spinner, and then rending the page when the data has loaded. Phew!
Here, we've skipped several of those steps by directly accessing the database and returning the result in our JSX. If I needed to, I could massage the data within the component as well, work that otherwise would have required a separate API to handle or would need to be done on the client.
Colocation
The main paradigm shift here is colocation in favor of separation of concerns. The first time writing a db query in a React component is a jarring moment! But, colocation is a trend we've seen in motion even with CSS in JS libraries. This furthers it by having all server related code and templating code in one react server component.
For complex apps, this colocation can be a nice DX improvement, with all the relevant business logic not far from the template. All the while, the option for abstraction and decoupling is still available.
Many more thoughts on this, but I'll leave it there for today!
April In Paris
I never knew the charm of spring~ Never met it face to face 🎵
Louie and Ella have my favorite rendition.
Kermit!

Watching the Muppets Show. Never knew that Dizzy Gillespie was a guest star on an episode!
JWTs and Database Sessions from an Architecture Standpoint
This week: A quick look at two session persistence strategies, JWT's and Database storage.
I'm taking a break from the specific implementation details of OAuth login and credentials sign in with Next Auth. Today, a broader, more widely applicable topic.
Remember Me
In the posts linked above, we looked at how to verify a user's identity. Once we've done that, how do we keep them logged in between opening and closing their browser tab?
There are different ways to manage the specifics of these approaches, but I'll be referencing how it's handled in Next Auth since that's where my head has been!
With that in mind, the two that are todays topic are storing authentication status in a JWT or storing session data on the Database.
Database
More conventional in a standalone application, database sessions will sign the user in, store details about their session on the database, and store a session id in a cookie. That cookie is then sent between the server and client for free with every request without any additional logic written by the client or server side code.
Once the user has stored the cookie in their browser, they have the session id for each page request across tabs and windows. With each request, the server will verify the session by looking up the record in the database. Any changes made to the user (permissions, signing out) are handled on the db.
The pros:
The cons:
JWT
The JWT can be implemented in a similar way: Cookies can be used to transport the identifier. However, the difference here is that session data is stored in the Jason Web Token, with no database backing the session. Instead, an encrypted token along with a unique secret with hashing can be used to verify that a token is signed by your application's server.
So, instead of database lookups with a session id, your application's secret is used to verify that this is a token administered by your application.
The pros:
The cons:
Conclusion
The cons for JWT are mostly added architecture, while the cons of the database are storage and db request related. If using a distributed, highly scaled system: JWT's lend several strengths to mitigate the cost of complex systems interacting together as well as a high volume of data. For more stand alone applications, however, perhaps the added overhead of managing a JWT strategy is outweighed by the benefits of a simple DB strategy
PS
I just realized I've written on this exact subject before! D'oh!
In The Gist on Authentication, I wrote about authentication methods from a security standpoint, highlighting best practices to avoid XSRF attacks.
Well, over a year later, I'm thinking more here about performance and scalability. So this one's a keeper. If playing the blues has taught me anything, it's that we're all just riffin' on three chords, anyway!